What’s new at Inera and around the industry
April 2018 Newsletter

Why you’ll love the eXtyles Support Portal, what’s new with Font Audit, and more in the April 2018 Newsletter!
In praise of the eXtyles Support Portal
Have you been sending us your eXtyles support queries by email? Why not turn over a new leaf this spring by switching to our Support Portal? Here are just a few reasons we think you should give it a try:
1) It’s easy!
Once you’ve spent 30 seconds creating an account on Inera.com, you’ll have access to a whole world of tools to help you organize your interactions with Inera.
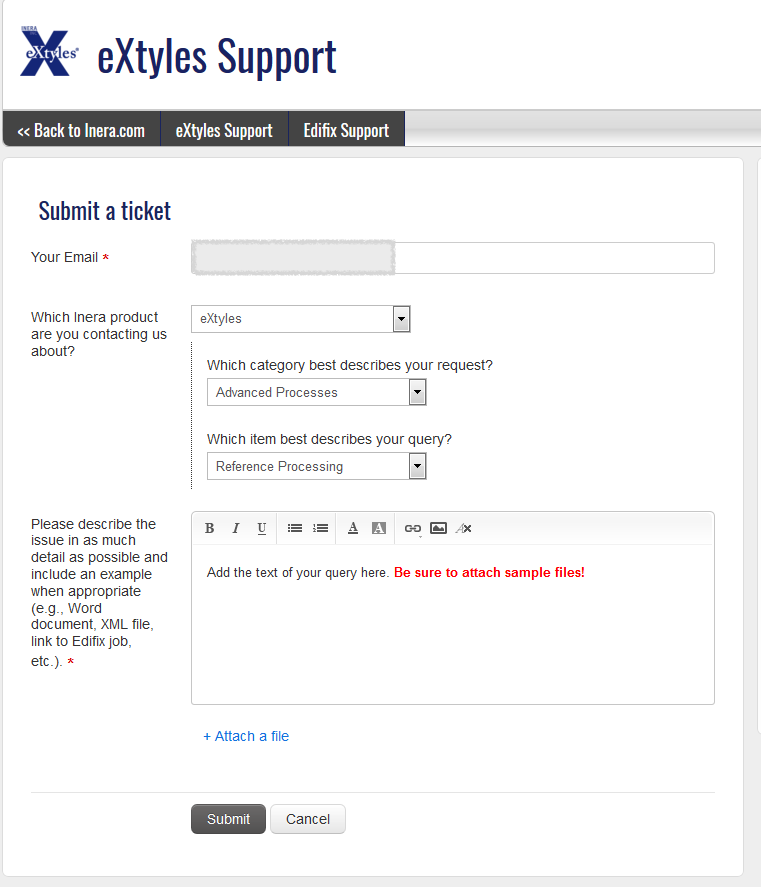
Create a ticket via the Support Portal

The portal’s Conversation view, where you can keep track of interactions with Inera’s agent
2) It’s soothing!
In one location, you can see the status of all your support tickets—no more support emails lost in your inbox.

View the status of all your tickets in one convenient place
3) It’s orderly!
Your team lead can view and manage support tickets for everyone in your organization—just ask us to make the appropriate person a team lead.
Spotlight on eXtyles Font Audit
eXtyles Document Audit > Font Audit analyzes the fonts used in a Word file and gives you an overview before you begin eXtyles processing. The next time you run Font Audit on a document, take a few seconds to look at the audit results—you may be surprised! We’ve recently revamped the Font Audit process to make the results more helpful to eXtyles users.
Now when you run Font Audit you should see the following new features:
- A list of fonts found in the document, each marked as Supported, Unsupported, or Unknown
- A message warning you if any unknown or unsupported font is present in the document, along with suggestions for how to check whether anything has gone wrong (as in the example shown below)

Why is this new information useful? For an example, see this month’s Word Fail.
Catch Inera at JATS-Con 2018!
CEO Bruce Rosenblum will be talking eXtyles Metadata Extraction during the JATS Vendor Showcase at 1:30pm on April 17. Bruce is also presenting two JATS Mini Tagging Tutorials on April 18, on the JATS element private-char and on JATS markup for references to conference proceedings.
On the Crossref blog: How we use Crossref metadata
In this 8-minute read from the Crossref blog, Inera’s Bruce Rosenblum takes the stage to answer questions about how Inera’s software uses Crossref metadata.
Find Inera at upcoming conferences
 ► JATS-Con
► JATS-Con
Bethesda, MD, 17 & 18 April
Inera’s Bruce Rosenblum and Joni Dames will be attending this year’s JATS-Con, the peer-reviewed, NLM-hosted conference on all things JATS—but also all things BITS and STS! The full JATS-Con program with abstracts is now available. See above for more on Bruce’s talks during the JATS Vendor Showcase (April 17) and the JATS Mini Tagging Tutorials (April 18)!
 ► Council of Science Editors Annual Meeting
► Council of Science Editors Annual Meeting
New Orleans, LA, 5–8 May
Inera’s Elizabeth Blake and Jennifer Seifert will be attending CSE 2018, and Elizabeth will once again be an instructor for the Short Course for Manuscript Editors! In addition, she will be presenting at the session “The Good, the Bad, and the Ugly in Citations,” May 8 at 4:00 p.m.
 ► Society for Scholarly Publishing Annual Meeting
► Society for Scholarly Publishing Annual Meeting
Chicago, IL, 30 May–1 June
Inera’s Elizabeth Blake, Bruce Rosenblum, and Sylvia Izzo Hunter will be attending this special 40th anniversary edition of the SSP Annual Meeting, and Bruce will be co-chairing a session with Christine Orr of Ringgold titled “Metadata and Persistent Identifiers through the Research and Publication Cycle.” We’re excited to announce that this session has also been chosen for SSP’s second annual Virtual Meeting track!
Attending one of these events? We’d love to see you! Please contact us if you’d like to schedule a meeting.
Working with Word
Epic Word Fail: I know Unicode exists, I just like my way better
► The Fail:
Your roving reporter once met a very long, very phonetics-heavy linguistics book whose author (not surprisingly, a linguist) had, disregarding instructions, used their preferred specialty font to render all International Phonetic Alphabet (IPA) characters used in the book—hundreds of instances of dozens of characters such as ə, ʔ, ʷ, ā, and ɤ. The font in question is proprietary (and not inexpensive), and (again, not surprisingly) no one else involved in producing the book had it installed on their computer.

You might think that this wouldn’t be a problem; after all, virtually every IPA character can be represented by a Unicode entity (or combination of entities), and so what if they look slightly different in different fonts? Alas, you would be wrong: this particular font does something quite different, which is to map IPA character glyphs to entirely different Unicode entities.
The result of normalizing fonts in a document created in this way—whether by activating as an eXtyles document or simply by applying your preferred editing font throughout to save eyestrain—will be a mess of peculiar characters (or occasionally pairs of characters) that make no sense in context and bear no resemblance to what the author intended.
► The Fix:
As is so often the case, this problem is best solved by not creating it in the first place. The universe of Unicode entities is vast (and growing!), and chances are very good that you can find what you need. Furthermore, many of the most common font families, including Times New Roman and Arial, have large glyph sets that include a wide range of “unusual” characters such as those used in IPA.
→ eXtyles tip: eXtyles Font Audit lists the fonts used in your document, and the newly revised Font Audit warns about Unknown and Unsupported fonts, and suggests ways to detect errors! Read the Font Audit results dialog carefully, because you just never know.
If you’re farther downstream in the production process and “don’t do that” is no longer an option, you may have to do your character mapping by hand. The tools you’ll need are a PDF of the document generated by someone who has the idiosyncratic font installed, a PDF list of special characters used in the document (including both the characters themselves and their names, if possible), the Unicode Character Table, Word’s Find & Replace feature, and lots and lots of patience.

Remember that you can …
- check what Unicode entity underlies a particular glyph by selecting the character and hitting Alt-x
- search for specific characters in a specific font via More > Font in the Find & Replace dialog
- replace the contents of the Find box with the contents of your clipboard by copying the thing you want and then typing ^c in the Replace box
Have an intractable Word problem you’d love to solve? Have a clever tip to share? Send it to us at [email protected]!